Integrating Systems of Intelligence, Engagement & Agency
Premise
Both Snowflake and Databricks want to be the “goto” platform for building AI-driven applications. Each firm however is taking a different route to get there in our view. In our model of the new AI software stack, we see three requirements for any company to achieve the aspiration put forth by these two data companies. Specifically, any firm that desires to be such a platform must have three key components:
- System of Engagement (SoE) – A generative user environment that converts intent into a user experience that understands business context.
- A System of Intelligence (SoI) – That incorporates a 4D map of an enterprise to harmonize the application estate, not only to answer what happened, but why it happened, what’s likely to happen and what should be done next.
- A System of Agency (SoA) that can both ask these questions and operationalize the answers to the system of record.
In our view, the most critical element of this 3-layer cake is the system of intelligence. Without the SoI, which encapsulates the data intelligence, the other systems are less capable. For example, the SoE relies on the SoI to present a summary of the proper business context. In turn the SoA needs the SoI to navigate the state of the business. The interaction of these three layers itself enriches the system of intelligence, creating a flywheel effect.
At Snowflake Summit we saw Snowflake begin to build what we’ve referred to as the SoI, by taking the first step of importing metric and dimension definitions from third party tools and making them first class citizens. At Databricks Data + AI Summit, Databricks took a similar step by adding the ability to define and share metric and dimension definitions with users and third party tools. While this may sound trivial to some, we see this as an initial building block of the SoI, the keystone of the future software stack and one that has not received enough attention from most of the industry.
In this Breaking Analysis we dig deeper into the announcements from Databricks Data + AI Summit and analyze the company’s moves in the context of our industry software model. Importantly, our research stems from an understanding of what we see as customer needs beyond an historical system of truth. Specifically, customers desire a system that can inform and/or automate decisions that span the current silos of the application and data estate. Moreover, data platforms are “Crossing the Rubicon” into new territory where analytics and agents drive traditional operational applications.
Beyond Individual Products: A System in Formation
While Databricks has built impressive individual capabilities across data intelligence, user experiences, and agents, a deeper strategic pattern is emerging from their recent product introductions. The company’s investments in Unity Metrics, Databricks One, Genie, and Agent Bricks aren’t simply expanding product features – they’re constructing the foundation for what could power a “Service as Software” (SaSo) platform that delivers business outcomes rather than just a data platform or a SaaS application.
The Learning Flywheel Advantage
Understanding the strategy lies in recognizing how Systems of Intelligence, Systems of Engagement, and Systems of Agency can create a learning flywheel. When users interact with Genie, Databricks One and ideally Apps, they enrich the semantic understanding captured in Unity Metrics, formerly 2 1/2D maps of analytic data traditionally silo’d in proprietary BI tools. In the future, as that semantic foundation grows into a richer 4D map of the enterprise, agents built using Agent Bricks can inform or operationalize more sophisticated processes. When agents learn successful patterns that need to be repeatable, precise, and explainable, human supervisors can “materialize” their behavior back into the intelligence layer, creating a self-reinforcing cycle of improvement. Data intelligence is the heart of this system and that explains why Ali Ghodsi called it “existential.”
This integration effect could transform Databricks from a data platform into something fundamentally different. Unlike traditional SaaS that manages workflows, this architecture could deliver actual business outcomes under human supervision, such as converting prospects into customers and fulfilling the services they buy. In other words, it would deliver service as software.
The Competitive Challenge
While Unity Metrics establishes a key foundation in dimensional semantics for analytics, it represents nascent progress toward comprehensive enterprise data intelligence. New competitors converging on this capability have developed significantly more mature data intelligence in harmonizing application semantics within their specific domains. SAP’s Business Data Cloud brings deep ERP semantics, Salesforce’s Data Cloud models customer profiles and engagement journeys, ServiceNow’s Workflow Data Fabric starts to build out horizontal departmental processes, and Celonis has built process execution capabilities that abstract legacy systems.
The Critical Window
The fundamental question becomes whether Databricks can successfully bridge from dimensional semantics to comprehensive application semantics before competitors extend their domain-specific advantages into generalized platforms. Ali stated that Databricks aspires to support common application workloads such as customer data platforms and security. Agent Bricks — which currently builds informational agents but not yet operational workflows — is far more sophisticated than any offerings we’ve seen. However, competitors with richer Systems of Intelligence may be able to compensate for weaker agent development tools. Agents are ultimately “programmed” by the intelligence of the data on which they train and operate.
The Transformation Imperative
Databricks recognizes that competitive differentiation for its customers in this emerging landscape comes from feedback loops that an integrated platform enables. The vendor that best enables their customers to create these learning flywheel effects first may well define the next era of enterprise software platforms.
What follows is our detailed analysis.
Databricks’ Data Intelligence Stack: From Lakehouse Foundations to Agentic Autonomy
Following on the heels of Snowflake’s push beyond warehouse economics and into nascent Systems of Engagement, Systems of Agency, and transaction processing, Databricks is aggressively pursuing a similar destination – but via a different path and with a more expansive thesis. What Databricks calls “Data Intelligence” is its reimagination of the enterprise data stack – i.e. an end-to-end architecture designed not merely to store and process data, but to act as a substrate for intelligent, agentic applications that interact with and act on behalf of humans.
Exhibit 1 below shows a multi-tier stack with the Databricks infrastructure (e.g. Lakehouse and open data) at the base – table-stakes at this point. Above (and next to) that sit three critical blocks of functionality:
- System of Engagement – the AI-powered front-end that maps user intent into intelligent interactions with analytic and eventually operational data.
- System of Intelligence (SoI) – a digital representation of a business’s end-to-end operations; rather than silos of BI and ML models and application logic, they become a harmonized enterprise asset, just like analytic data. Databricks refers to this as data intelligence, and today it encompasses the metrics and dimensions that were previously confined to BI tools. However, they have bigger ambitions.
- System of Agency – software agents able to reason about business operations by tapping into the SoI, in collaboration with humans, and ultimately take autonomous action through Systems of Record (SoR). Today each SoR is a silo with its own business logic. But that will migrate into the SoI and analytics and agents will eventually only invoke them for their transactional logic.

At the foundation of this architecture sits the familiar Lakehouse construct, along with Databricks’ newly established transactional services. These are no longer the story; they’ve become table stakes. The new story is in the emerging layers above: those that reflect a re-architecting of software to support agentic behavior and generative intelligence governed by a universal semantic layer, the System of Intelligence.
In our view, Databricks – like Snowflake – is ascending Geoffrey Moore’s strategic hierarchy. First, it enables generative AI to become the new user experience. Next, it introduces agents – software entities that don’t just provide answers, but also take actions under human oversight. These agents are grounded in data intelligence, the semantics governed by Databricks’ Unity Catalog. Unity aspires to serve as the foundation for all enterprise data and AI workloads.
Ali Ghodsi, Databricks CEO, has made the stakes clear. At Analyst Day, he called owning semantics “existential.” In our view, this is the cornerstone of the company’s Data Intelligence strategy. Data drives AI, and in the enterprise, the ability to encode and refine semantics – how the business actually operates – will determine how effective and differentiated each company’s AI becomes. It’s not about having the most powerful analytic engines or the most advanced frontier models. Those are commodities. The true differentiation lies in each enterprise’s ability to construct a dynamic, real-time map of its operations – a “system of intelligence” that fuses past context, present signals, and future scenarios.
The goal is to enable agents that not only know what happened (metrics and dimensions), but can also infer why it happened, predict what’s likely to happen next, and prescribe what to do about it. This, we believe, is the holy grail of enterprise AI – the foundation for what we’ve called “Enterprise AGI.” And the vendors that can help enterprises build a 4D map – a kind of operational digital twin of an enterprise – will become the operating systems for enterprise data and AI. That is the aspiration Databricks has laid out. The question now is: how far along are they, and where do critical gaps remain?
Databricks One and Genie: Re-Architecting the Front Door for AI-Driven Engagement
To understand how Databricks intends to operationalize its data intelligence vision, we zoom into a specific segment of the emerging software stack that George Gilbert has posited. The System of Engagement is our focus in this section of the Breaking Analysis. In our framework, this layer acts as the front door for business users, and at this year’s Data + AI Summit, Databricks made a clear move to redefine that entry point. Exhibit 2 below shows a close-up view of our framework, with the System of Engagement block ringed in red, situated directly to the left of the SoI. This picture depicts the Genie interface, which lets end-users “talk” to data. It converts user intent into SQL and generates an interactive visualization in return.
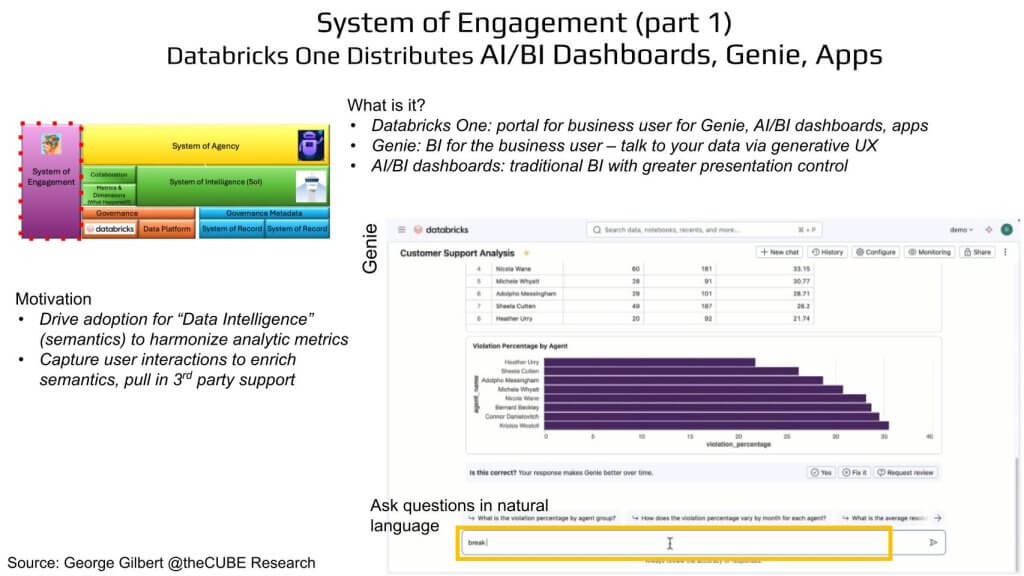
Why the UX Land-Grab Matters: Drawing Third Parties Into Enriching Its Data Intelligence
At Data + AI Summit, Databricks introduced Databricks One, a unified user experience built to serve non-technical users – i.e. analysts, line-of-business operators, and executives – who increasingly need to interact with data in natural language. Databricks One bundles together Genie (its generative BI front-end), traditional dashboards, and a growing suite of packaged applications under a single portal. But this is more than a UI refresh. In our view, this represents a foundational re-architecture – one that unifies how users engage with data, AI, and applications and funnels all interactions back into a centralized semantic spine.
The intent is twofold. First, to standardize metrics across departments and eliminate the common enterprise dysfunction of debating whose dashboard is correct. Paraphrasing Ali Ghodsi who remarked that this move aims to end “the endless arguments in meetings about where the numbers came from.” Second, by capturing user intent through every query and interaction, Databricks is enriching its underlying semantic layer, which will, in turn, allow agents to operate with greater precision and confidence.
This push into BI should also be interpreted as a strategic signal to the ecosystem. By securing the user experience layer, Databricks creates an opportunity to invite third-party applications to build on top of its semantic and intelligence infrastructure. But as we noted in last week’s Breaking Analysis on Snowflake, the company will face real competition from specialist BI vendors with deep expertise and entrenched customer relationships. The open question is whether Databricks can successfully use the System of Engagement UX layer to draw other vendors into enriching its data intelligence, what will ultimately be the System of Intelligence or whether the two systems will remain disconnected.
To illustrate the significance, George offers a compelling analogy – just as the proliferation of smartphones created the need for a more scalable, resilient backend in the form of cloud computing, so too does a new system of engagement require a more intelligent backend – what Databricks is calling data intelligence, their term for the System of Intelligence. Traditional dashboards, where users manually craft visualizations , are being augmented or replaced by a generative interface where the system itself responds to user prompts by either retrieving relevant visualizations or creating new ones dynamically.
But none of this works without the underlying data intelligence layer. That’s where gold data products – defined by clear metrics and dimensions – become essential. The feedback loop between the system of engagement and the system of intelligence is not merely supportive; it’s symbiotic. Each powers and improves the other.
In our view, Databricks One, Genie, and AI/BI are more than UI veneer. By coaxing users to talk to the data in natural language, every query, click, and visualization can be routed back to enrich Unity Catalog’s metric definitions. Over time that creates a flywheel as described below:
- User Intent Feeds Semantics: Each question ultimately enriches the catalog with richer context, adding meaning to the data so that others can extract more value from it.
- Semantics Feed Agents: Richer context arms agents to make better decisions and ultimately to act autonomously.
- Agents Create Outcomes: Agents deliver outcomes more effectively aligned with business objectives.
BI as an On-Ramp for Intelligence: An Example using Sigma to Close the Loop
In this next section we’re going to use an example of a BI company called Sigma, a spreadsheet-native notebook front-end already popular inside many shops. Think of Sigma as having cells with end-user objects like spreadsheets instead of programmer-friendly dataframes, but with a lakehouse backend and, increasingly, GenAI-mediated interactions.
Exhibit 3 below keeps the red call-out around the System of Engagement block within George Gilbert’s framework. Sigma has announced integration with Unity Catalog for its metric definitions. This integration ideally will contribute to the data intelligence flywheel Databricks is trying to start.

In our view, Sigma is evolving into a kind of citizen development platform, one where business users aren’t simply cutting and pasting data or consuming dashboards, but are instead crafting lightweight data apps – tools that reflect specific domain logic and workflows – all within the governance and semantic framework of the Lakehouse.
This matters for two reasons. First, it neutralizes Snowflake’s early momentum with BI partners like Sigma by elevating the tool as a first-class citizen on the Databricks platform. Second, and more strategically, it points toward a future where business intelligence apps like Sigma, or even Microsoft Power BI (which Satya Nadella explicitly called out during the Databricks Summit), can trigger operational workflows. In that model, the BI front-end doesn’t just visualize metrics; it reflects the trusted System of Intelligence and can seamlessly convert insight into operational transactions.
George expands on this vision, framing it as the next evolution in BI – from visual storytelling to intelligent data applications. These tools go beyond static dashboards and natural language Q&A – they enable the analytics layer to directly inform operational systems. Whether that means recommending next steps, flagging anomalies, or triggering actions in downstream systems, the intent is to close the loop between insight and execution.
A real-world example of this model exists today in the form of Blue Yonder’s advanced supply chain app runs on Snowflake, with Sigma supporting the planning front ends and RelationalAI underneath. This combination integrates dimensional semantics (think OLAP cubes) with full operational application semantics. It’s an early but powerful illustration of where this ecosystem is heading.
To be clear, the Blue Yonder deployment is running on Snowflake. But the implication is broader in that both Snowflake and Databricks are heading toward the same destination – enabling semantic-rich, operationally aware, intelligent data applications that unify decision-making and action. In that journey, BI tools like Sigma aren’t just visualization engines. They are the user-facing gateway into the enterprise’s system of intelligence.
And once again, the glue that holds all of this together is data intelligence. Without harmonized, governed, and enriched semantics, none of these capabilities—whether dashboards, agents, or operational applications—can integrate and function at enterprise scale.
From 2.5-D Snapshots to a 4-D Enterprise Map
In our view, Databricks’ ‘rule the world’ aspiration is that every analytic, ML model, and agent should draw from a single, governed source of metrics and dimensions managed in Unity Catalog. At its Data + Summit, Matei Zaharia hammered this point, contrasting Databricks’ “one governance engine” with Snowflake’s Polaris + Horizon combo that only syncs permissions, not data semantics.

Exhibit 4 above shows a customer-support example in which three joined tables – Tickets, Agents, and Resolutions – feed a small yellow “Data Intelligence” box. The graphic illustrates how Databricks lifts BI-style cubes (dimensions and measures) out of individual dashboards and inserts them in Unity Catalog, making them a shared, governed resource for all tools.
Where We Are Today: 2½ Dimensions
In our view, Databricks has successfully transformed what used to be isolated data marts into shared, queryable assets. But this is still a narrow, two-and-a-half-dimensional snapshot – i.e. strings elevated to things inside a single business domain (e.g. customer support). It answers what happened inside that silo with consistent metrics and no Excel debates, which is important progress. We believe the scope of the metric definitions is narrow because of the current state of Databricks’ text-to-SQL generation technology. Complex queries against complex schemas are more challenging. And it falls short of our vision of a real-time digital representation of a business. That will take more time.
Where the Industry Needs to Go: 4-D System of Intelligence
We believe enterprises ultimately need a 4-D map of people, places, things, and processes, over time —spanning every aspect of the business. At that point, agents will be able to tackle my more transformative problems, such as:
- Why did a support spike occur?
- What supply-chain bottleneck is most likely to prevent us from achieving our revenue growth objective?
- Which proactive action will remediate that supply chain bottleneck?
Getting there means abstracting beyond RDBMSs and tables, to a unified semantic knowledge graph that cuts across sales, fulfillment, returns, finance, the ecosystem, and beyond. Databricks insists Unity Catalog is architected for that aim, but today’s metrics & dimensions block is the starting point in our view, not the destination.
The Strategic Payoff
Our belief is that moving metric and dimension definitions into Unity Catalog is the crucial first step because it:
- Decouples Semantics from Tools – Where BI vendors consume shared definitions instead of using silo’d definitions embedded in their proprietary tools.
- Creates a Feedback Loop – i.e. every query enriches the catalog, steadily building context into the enterprise map.
- Sets Up Agentic Workflows – Once the map matures, agents can reason over why and what next, not simply report historical KPIs.
It can be argued that Databricks is ahead in open governance unification, but it is still early on with respect to the breadth and depth of the semantic model. The race now hinges on how fast it can evolve these 2.5-D snapshots into the comprehensive 4-D System of Intelligence that our vision of enterprise AGI will demand.
Moreover, while Databricks’ marketing masterfully de-positions Snowflake’s otherwise clever Horizon to Polaris integration, messaging the avoidance of lock-in, customers understand that Unity itself creates a moat for the company and its own form of lock-in. “Open” is a moving target.
The point is, Snowflake is doing a balancing act in its own right, slowly trickling Horizon functionality to Polaris as the open-source catalog matures. If it plays its cards well, Snowflake can counteract the lock-in message and, to its loyal base anyway, deliver enough value and simplicity in AI to keep customers in the boat. The real question is how will companies like Snowflake and Databricks move up the stack, and to what degree will they participate in what we see as the all-important SoI layer?
Building the Semantic Flywheel: From Snippets to a Governed Digital Twin
Databricks investments in Genie, AI/BI, and Databricks One reveal that it believes business user engagement is not merely an endpoint – it’s the beginning of a virtuous cycle. At the heart of this cycle is a growing ontology of metrics and dimensions, enriched through user interaction with tools like Genie. What was once the domain of centralized data engineering teams is now becoming a shared, governed artifact that evolves with every user interaction.t
In one illustrative example, Genie auto-surfaces snippets of knowledge for an administrator based on connecting user intent with data—such as metric definitions—keeping a human in the loop at all times. This is critical. Databricks emphasized the need for oversight as this knowledge base grows. The idea is to treat every business-user query, every dashboard interaction, as a signal—one that feeds into a shared semantic graph. As that graph becomes richer, it doesn’t just power traditional BI dashboards; it feeds into downstream workloads like machine learning and, ultimately, fully agentic workflows.
Exhibit 5 below shows a screenshot where Genie surfaces a highlighted “knowledge snippet” card – Tickets Resolved Rate – including its formula and dimensional filters. At the bottom of the card is an “Accept” button for an administrator, and a status banner indicates whether the snippet has been promoted to Unity Catalog. A circular process is implied where an operator goes from “User Query” to “Proposed enrichment” to “Admin Review” to “Catalog Publish,” depicting the flywheel that enriches the ontology with every interaction.

In our view, this represents a meaningful inflection point for the data ecosystem. If Databricks can capture and curate richer versions of this metadata at scale – deduplicating and governing it effectively – it sets the stage for what many in the industry have long envisioned – i.e. a living, digital representation of the enterprise. A true digital twin, built not just from structured data tables but from the collective knowledge embedded in how users interact with data. Metrics and dimension definitions are a first step on a long journey to that destination. Capturing, designing, and governing a digital twin that harmonizes all the business logic in the legacy application estate will require far more sophisticated tools and platforms.
But this opportunity comes with risk. Without strong curation, semantic sprawl becomes a risk. Unchecked definitions could lead to conflicting insights and fragmented decision-making – a problem that has plagued self-service BI for over a decade.
The underlying principle is that data intelligence should not be completely specified top-down in a vacuum by centralized engineers. Instead, it must emerge from user interactions—and be curated centrally within a robust framework.
This architecture links the system of engagement (where insights are generated and consumed) to the system of intelligence (where semantics and meaning reside). It’s this connection that fuels the flywheel – i.e. as more tools adopt Databricks’ semantic layer, more users engage with governed data, and more intelligence is captured and fed back into the model, steadily expanding the map.
Today, this intelligence layer remains a set of narrowly scoped, two-and-a-half-dimensional snapshots—for instance, dashboards focused on customer support. But the vision is much more expansive. The goal is a full, end-to-end, four-dimensional map of the enterprise. A governed semantic layer that captures not just metrics, but all the digital artifacts—events, decisions, workflows, intents—that define how a business operates.
That’s the ultimate prize – i.e. a unified, living system of intelligence that informs agents, aligns teams, and guides enterprise decision-making at scale.
Unity Catalog as Clearinghouse: The Fight to Own Enterprise Semantics
Databricks positions Unity Catalog not just as a governance layer, but as the semantic clearinghouse for an expanding network of data and analytics partners. The vision is alluring – i.e. enable all tools in the analytics value chain – Tableau, ThoughtSpot, Hex, Sigma, Monte Carlo, Collibra, and others – to both consume and contribute to a shared ontology. This turns the catalog into a strategic moat, embedding Databricks deeper into the fabric of enterprise data operations.
Exhibit 6 below shows in the middle of the graphic a bold “Unity Catalog Metrics” hexagon connected to multiple ecosystem tools and partner logos – Tableau, ThoughtSpot, Hex, Sigma, Monte Carlo, Collibra, and others. Each spoke implies a bi-directional path that both consumes and contributes. The idea is this depicts a shared ontology feeding business context underscoring Databricks’ goal of making Unity Catalog the clearinghouse for enterprise data intellgence.

The ambition here is not simply to standardize definitions. It’s to create a shared layer of enterprise context that sits above the raw data itself. Two strategic questions naturally emerge.
- Will third-party vendors truly round-trip semantics, or siphon definitions into proprietary silos?
- As zero-copy federation spreads, does controlling meaning outrank owning data?
When queries can reach remote stores at runtime, the value shifts from where the data is stored to who owns the definitions.
Comparing this approach to Snowflake is instructive. Snowflake supports the import of third-party BI semantics – e.g. LookML – to seed or extend its native semantic views. Those views, today, appear somewhat broader in scope than what Databricks has unveiled.
Both want to own that layer. Not the raw data, but the model of the data – the contextual definition of how the business works. That’s where lasting value resides. In fact, this principle is already being tested elsewhere. In Salesforce’s Data Cloud, the company prominently showcases its zero-copy federation capabilities. What’s most valuable isn’t the raw data – it’s the customer profile and engagement model that Salesforce has built. The semantics, not the data storage, create the differentiation. In a similar way, Databricks is betting that the battle for AI-native data platforms will be won not by who owns the data, but by who owns the model that defines it.
Databricks’ proposition is elegant and simple – i.e. let every tool in the analytics value chain both read from and write to a common ontology. If successful, the catalog becomes a moat around enterprise context – stickier than the data itself. If Databricks convinces the ecosystem to feed into, and extract from, Unity Catalog, the platform owns the map that agents will navigate.
ETR Evidence of Databricks’ Strong Trajectory in Database
Let’s take a breath from the architectural diagrams and bring in some survey data from ETR. Exhibit 7 below shows that Databricks has made some notable strides in the market as it pertains to database and what it refers to as lakehouse. The graphic shows Net Score or spending momentum on the vertical axis and Overlap or penetration into the data set on the horizontal axis. The point we’re trying to emphasize is the progress that Databricks has made and the inroads into Snowflake’s strength in data warehousing. Notice the position of Databricks in January of 2023 and where it is today on the map, with a highly elevated Net Score on the vertical axis at 46.2%, well above that red dotted line at 40%, which is considered highly elevated.

Moreover, Databricks has meaningful penetration into the market, more than most people thought they would in this space (us included). Essentially they’ve come from nowhere in database/data warehousing to a leading brand associated with data lakes, lake houses, and now with the Neon acquisition, which they’re calling Lakebase, they’re trying to redefine traditional transaction databases.
In the previous chart we were talking about the data intelligence that feeds the system of engagement front end to the data intelligence underneath, which sits on top of a data platform and eventually grows into a system of intelligence. So what Lakebase or the Neon technology delivers is a cloud native Postgres database, somewhat like what Amazon did with Aurora Postgres, but with additions, bidirectional synchronization to lakehouse tables and crucially, the agent native development capability, which is the ability to fork an entire database by an agent using copy on, write.
It works ephemerally just like the agent. Already a large majority of Neon databases are created by AI coding agents, for instance, Cursor. This, in our view, looks like the marriage of analytic and operational databases, and at the very base of that Exhibit 6 diagram, the traditional data platform and the traditional system of record, but they don’t have to be one engine. We saw with Snowflake that Unistore proved to be too hard. This forced the company to ultimately buy Crunchy as its Postgres database, which isn’t cloud-native.
So now Databricks has two cloud native databases, one for analytics, one for operational data, one informs decisions, and the other operationalizes those decisions in the form of a transaction. Databricks’ position on the graph in Exhibit 7 above is only going to be improving because they can now handle both those workloads. The big issue right now is that it addresses greenfield apps not legacy interoperability.
Why this matters:
- Architectural fit: The flywheel we outlined – Genie at the front, Unity Catalog at the core – requires a foundation that serves both analytic and operational workloads. Lakebase delivers a Postgres-compatible engine that syncs bidirectionally with Delta tables, enabling agents to fork an entire transactional database via copy-on-write, run ephemeral experiments, and rewind state without polluting production.
- Market momentum: Customers we think will reward that completeness. Maintaining a Net Score north of 40% while tripling penetration is impressive validation that the lakehouse narrative has crossed from buzzword to budget line.
- Expansion vector: Today the focus is greenfield applications. Legacy interoperability remains a challenge.
In short, Exhibit 7 shows the financial smoke behind the architectural fire. Going forward, we think Databricks’ data-intelligence vision is not just technically coherent, it will pull real dollars and workloads away from entrenched warehouse incumbents and vie for new workloads. The logical next question is can the platform parlay this momentum into legacy estates before rivals shore up their own semantic moats?
Lakeflow Designer Brings No-Code Pipelines to the Lakehouse
After establishing a foundation around semantics and user engagement, Databricks is also focusing on simplifying the data engineering layer. At the 2025 Data + AI Summit, the company unveiled LakeFlow Designer, a no-code canvas that enables natural language prompts to automatically generate declarative data pipelines. These pipelines are anchored in Unity Catalog, ensuring they remain governed, trackable, and semantically consistent with the broader data intelligence model.
Exhibit 8 below describes this in greater detail. The graphic splits into two panels. The left side zooms in on the “Data Platform” band of the stack, outlined in a red dashed box to show where Lakeflow Designer lives.

The right side shows a canvas UI for Lakeflow Designer. A natural-language prompt bar is prominent along with with GUI drag-and-drop boxes – Franchise details, Transaction history, Aggregate Franchise revenue. Natural language instructions can generate candidate pipelines with transformations. A pop-up join editor, for example, lets the user edit the suggested Inner, Left, or Right join, while an “Accept / Reject” bar (human in the loop) beneath the canvas mirrors the approval flow seen earlier in Genie. A grid at the bottom previews output rows.
What’s new is the no-code pipeline builder augmented by natural language, which generates declarative pipelines governed by Unity. The vision is to democratize pipeline development and enable business analysts to work with data engineers to extend lifecycle governance.
The intent is to collapse the traditional handoff gap between business analysts posing questions and engineers translating those questions into production-grade data workflows. By generating joins and transformations based partly on its data intelligence, Databricks is positioning LakeFlow as a kind of guided assembly experience – one that turns pipeline development from a brittle coding sprint into an intuitive, iterative process.
This move isn’t happening in a vacuum. It’s a necessary response to the increasing momentum behind business-friendly data ingest and transformation pipelines from vendors like Informatica, Salesforce, Palantir’s Foundry, and ServiceNow’s low-code automation stack. Each of these competitors has invested heavily in the data intelligence that makes low-code/no-code abstractions possible and can bring non-technical users into the data lifecycle. The open question for Databricks is whether its semantic layer is mature enough to generate meaningful pipeline suggestions with the same level of precision as these more established incumbents with deeper, though typically domain-specific, data intelligence.
What’s clear is that LakeFlow represents a major usability upgrade for the Databricks ecosystem. Instead of writing Spark code by hand, users are presented with a visual interface or natural language prompts that produce underlying pipeline logic automatically. But as with all generative systems, the effectiveness of this interface is entirely dependent on the richness of the underlying data intelligence.
When semantic context is deep—like what’s embedded in Palantir’s ontology engine, ServiceNow’s process models, or Informatica’s metadata graph—pipeline generation can happen with minimal intervention. In those environments, human users or agents can create and modify flows without having to understand every component in detail. The system fills in the blanks using a structured understanding of business entities, relationships, and constraints.
That’s the bar Databricks is reaching for with LakeFlow. And it’s part of a broader strategic aim: to enable business users to contribute directly to the creation of data products and AI applications, without waiting in line for engineering resources. Ultimately, the power of LakeFlow will hinge on the fidelity and adaptability of Databricks’ semantics—how well it understands not just the structure of data, but the intent behind it.
The open question is maturity. Platforms like Informatica and Celonis boast domain-rich ontologies that can auto-generate most of a pipeline before a human touches it. Databricks’ data intelligence must reach comparable depth for Lakeflow to deliver equal value. Today the UX is a dramatic improvement over Spark-based code…but users still need a working knowledge of the underlying data.
In our view, Lakeflow Designer sets the foundation to democratize pipeline creation, instrument every step with governance, and let the semantic layer grow smarter with each interaction. Whether it can match the precision of incumbents will hinge on how quickly Unity Catalog evolves from shared metric store to fully contextual enterprise map.
Bridging Predictive Power and Operational Action: The Rise of Graph Neural Networks in the Lakehouse
Kumo Shows How Gen AI Addresses Classical ML Friction
As the AI stack continues to evolve, the convergence of classical machine learning and generative AI is reshaping how data science workloads are built, governed, and operationalized. At the Databricks Data + AI Summit (and at Snowflake the previous week) this trend came into focus with the notion of third-party vendors like Kumo AI, whose graph neural network (GNN) engine exemplifies what becomes possible when foundation models are layered on top of raw, governed data.
Databricks’ roots are in Spark-driven data science and feature engineering. Exhibit 9 below shows how that heritage now gets disrupted by the graph-neural-network (GNN) revolution. Kumo’s pre-trained GNN foundation model ingests raw relational tables straight from Delta Lake, auto-infers relationships that once required painstaking feature engineering, and serves predictions. In effect, the tool collapses data prep and modeling into a single pass, which lowers the barrier for business teams to ask, “What’s likely to happen next?” and have the answer pushed directly into downstream systems.

Kumo’s value proposition is compelling. Its GNNs can ingest raw relational tables directly from the lakehouse and automatically infer connections – i.e. relationships that would have traditionally required extensive data engineering and feature engineering. In effect, Kumo extends Spark’s original mission – democratizing data science – by collapsing the distance between data prep, model training, and inference. Now, with the infusion of generative AI, this capability becomes even more powerful.
There are two strategic implications worth underscoring.
- Platform neutrality: Kumo runs natively on both Databricks and Snowflake, an explicit nod to multi-platform realities. But it also means state-of-the-art predictive ML modeling lives on both platforms. In the competition for workloads between the platforms, this is an equalizer.
- Democratization of prediction: Where BI answered what happened and metrics+dimensions began to address why, GNNs promise to commoditize what will happen? If Kumo models can be published to Unity Catalog, Databricks can keep that predictive context inside the same governed ontology that powers Genie and Lakeflow.
For years, enterprises have had solid tooling for understanding what happened, and increasingly why it happened. But prescriptive insight—action-oriented guidance that can trigger downstream workflows—has remained elusive. The promise of Kumo’s architecture is to push predictive analytics to the forefront, enabling both human users and agents to drive decisions directly into operational systems.
This model aligns with a broader shift toward open data supporting many compute engines. With the emergence of open table formats, new compute engines like Kumo’s GNN can now operate natively on governed data without requiring export, duplication, or vendor lock-in.
Historically, building predictive systems like this took armies of data scientists—something that tech giants like Google and Facebook invested in at scale. However, these capabilities are now becoming accessible to a much broader set of organizations. Pre-trained models, coupled with graph-based learning, make it possible to bypass many of the labor-intensive steps that used to define data science.
If BI tools gave rise to the age of dashboards, this evolution marks the onset of the intelligent assistant era—where asking “what’s likely to happen?” is as easy as the emerging natural language database queries. An open question is whether this remains just a partner offering or whether it becomes a native, first-party component of the platform.
In addition, we believe that disruption potential here is significant. Traditional ML pipelines m
ETR’s ML/AI Data Shows Snowflake Storming into Databricks Territory
Exhibit 10 below focuses on the ML/AI sector, where Snowflake has been traditionally been weaker. But as the data shows, the company has shored up its position because it focused on closing the gap and it has quality data in its platform to which customers can apply ML/AI.

The diagram shows the same XY axis as before – Overlap or penetration in the data set X Net Score or spending momentum. The point of the slide is that Snowflake wasn’t even registered in the data set back in January 2023. Today its position is above the 40% mark on the vertical axis and its penetration is greater than that of Databricks, which has had great success in the space.
Messages in the data
- Mutual encroachment is real. Databricks made headlines by muscling into warehouse economics; Snowflake is paying that back in the AI/ML arena. A year after first registering in this sector, Snowflake posts a 46 % Net Score—comfortably elevated, with penetration now edging past Databricks.
- Democratized data science is the next battleground. Both vendors want to collapse the historical gap between BI analysts and data-science specialists. If predictive ML becomes as ubiquitous as dashboards, the payback is the System-of-Intelligence real estate that dictates “what will happen” and “what should we do next.”
- Collision course broadens beyond two players. ServiceNow, Salesforce, Palantir, and future SaaS insurgents are also racing to own that SoI layer. We believe the vendor that blends governed semantics, low-friction ML, and agentic automation will be in a strong position for the next platform shift.
Implications
Snowflake’s surge validates the thesis that customers will straddle multiple clouds and analytic engines, choosing best-of-breed capabilities on a workload-by-workload basis; and choosing the best strategic fit. The fight from there moves up-stack, from who stores the data to who owns the meaning and predictive context. Databricks still holds the momentum edge, but Snowflake’s rapid entry proves the moat is penetrable. The winner will be the first to deliver a turnkey path from raw tables to governed semantics to predictive guidance, then loop that insight back into operational workflows without leaving the platform.
We don’t see this as a zero sum game. However traditionally, Databricks has appealed to a more technical buyer while Snowflake’s simplicity has attracted those customers who don’t want to mess with the plumbing. As generative user interfaces permeate, this could dramatically simplify Databricks deployments and appeal to a less sophisticated buyer. At the same time, Snowflake’s tight integration could deliver faster business outcomes for specific markets (e.g. Blue Yonder in supply chain) and be an attractive platform for developers.
Agent Bricks and the Push Toward a Declarative System of Agency
At the apex of the architecture Databricks is building sits the system of agency – i.e. the layer where the platform doesn’t just answer questions or generate insights, but takes meaningful action. The centerpiece of this ambition is Agent Bricks, a declarative framework designed to generate complete agent training pipelines and instrument them with detailed traces and evaluations (evals).
Exhibit 11 below shows a red-dashed box around the System of Agency layer at the top of our familiar stack. The right-hand panel shows an Agent Bricks console with four tile options – Information Extraction, Knowledge Assistant, Custom LLM, Multi-Agent Supervisor. We call your attention to the “What’s new?” sidebar which lists three bullets: “Declarative: Uplevels development,” “Agent Bricks: generate and self-optimize pipelines,” and “Natural-language feedback drives fine-grained optimization.” A second list labeled “Issues” flags current gaps – i.e. the inability to push insights into transactions, reliance on a new MCP interface for calling tools and any supporting application, and the narrow “action space” developers must still curate.

Upleveling agent development the way compilers upleveled high-level programming languages
Databricks wants the apex of its architecture to be more than a trivial “prompt wrapper” typical of many agent development tools. Agent Bricks is being positioned as a declarative framework that can auto-generate an entire agent development pipeline – retrieval, reasoning, tool invocation, fine-grained traces, and evals – then refine behavior with natural-language feedback instead of crude 👍/👎 prompts. The idea is that users will define the use case, select a tile, and let the platform orchestrate the rest.
This marks a significant evolution. Most agent tooling today is still focused on prompt engineering—designing clever ways to feed context into a chat interface. Under the hood, it’s little more than structured prompting wrapped in a workflow. Agent Bricks promises something different: a compiler-like approach where a business objective is declared – information extraction, knowledge assistance, multi-agent orchestration – and the platform builds the execution plan, the instrumentation, and the feedback loop automatically.
The analogy is that Agent Bricks aspires to be the SQL of agent development, where a high-level specification gets compiled into a plan of low-level actions, optimized and executed with minimal intervention.
Laying the groundwork for a Datadog for agentic applications
Traces are central to this design. Every step taken by the agent is recorded with fine-grained detail, forming the basis for debugging, optimization, and continuous improvement. One of the PMs demonstrating the technology at the booth said future agents would be able to learn from the traces to diagnose and remediate errors. In other words, you could see Databricks building a Datadog obervability platform for agentic applications.
Evals go beyond benchmark scoring, assessing whether the agent is actually achieving a defined business outcome – i.e. answering customer service questions correctly or nurturing a prospect through a pipeline. Importantly, Databricks is shifting feedback from simple thumbs-up/thumbs-down metrics to natural language evaluations, enabling richer context for feedback. The Agent Bricks optimizer figures out how to improve any and all components in the pipeline based on the feedback.
Expanding the action space with Model Context Protocol
Complementing Agent Bricks is support for MCP that allows agents to invoke external tools and applications. The vision is to give agents access to the broader enterprise landscape – not just generating insights, but triggering actions across systems. But this is nontrivial. Today’s agents still can’t fully push insights into transactional systems without hardcoded pathways. Developers remain in the loop for operationalizing decisions at scale.
That’s a key point. While Agent Bricks is conceptually a leap ahead of what most vendors offer, it remains at the stage of enabling informational agents – i.e. those that can assist, recommend, and summarize. Operational agents – those that can act autonomously across complex business workflows – will require tool-specific integrations.
But even with this innovation, the real constraint may not be tooling – it may be the underlying data intelligence. Platforms like Palantir, Celonis, ServiceNow, or Blue Yonder may not yet have the same declarative agent pipelines, but they’re sitting on rich 4D maps of enterprise operations. That depth of context – i.e. the ability to model business entities, relationships, temporal flows, and outcomes – offers another path forward: training agents via reinforcement learning against a digital twin of operations provides such an effective training environment that it can compensate for much weaker development tooling.
This is why data intelligence remains existential. The sophistication of the agent pipeline matters. But the ability of an agent to reason, act, and improve hinges on the fidelity of the map it’s trained on. The ideal scenario marries both: a powerful declarative tooling framework like Agent Bricks operating atop a fully governed, semantically rich 4D enterprise map.
That’s the future Databricks is aiming for. The architecture is forming. The question now is how fast the ecosystem – and their own data intelligence layer – can catch up.
From Workbenches to Real Applications: Converging Engagement and Agency
At the Data + AI Summit, Databricks made clear its ambition to move beyond the analytics workbench and into full-fledged enterprise application development and delivery. A key moment came during a demo that showcased how systems of engagement and systems of agency can converge – not just in dashboards or BI tools, but in business-grade applications that drive real action.
Exhibit 12 below again anchors on our familiar layered stack, shown at left, but this time a red dashed box spans both the System-of-Engagement and System-of-Agency tiers, signaling convergence as the headline, “Apps: Full Control – Soon Everything Comes Together” implies. The bullet list emphasizes that these apps offer more control than dashboards, support multiple UX frameworks (across Python, JavaScript), can be scaffolded by agentic coding tools, draw on every capability governed in Unity (Lakebase, DB-SQL, policy, etc.), and will ultimately embed Agent Bricks.
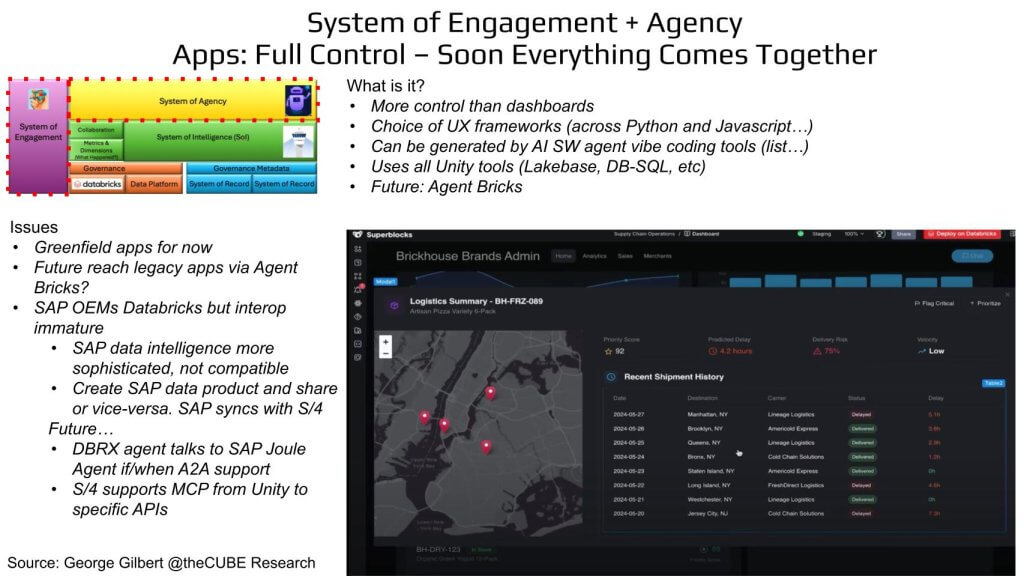
The right side of the graphic captures a dark-mode logistics application built with Superblocks. A map pins delayed shipments around New York; below, a table lists shipment IDs, destinations, carrier status, and delay times, all surfaced through Unity-governed data. A blue “Deploy on Databricks” button underscores that the app runs natively on the platform.
Dashboards are great at communicating what happened – and, increasingly, why – but the true enterprise value lies in answering “what should we do next?” And then taking that action. That’s the promise behind Databricks’ expanding application stack. Developers are now given multiple on-ramps: agent-based coding tools, Python and JavaScript front ends, access to the full Unity Catalog, DB SQL, Lakebase, etc. These components are unified under a single governed umbrella, abstracting complexity while preserving control.
The logical end state is that a governed environment where agents, semantics, operational and analytic data, and custom UX all intersect – yielding intelligent applications that are infused with context and capable of autonomous behavior. But Databricks still faces two major hurdles to reach that destination.
The first is interoperability. The story holds up well in greenfield environments, but real enterprise estates include deeply entrenched systems like SAP. Reaching those legacy platforms will require Agent Bricks to interface directly with SAP’s proprietary agents or APIs through the new MCP (Model Context Protocol) layer. That’s still early. Today, developers must hand-code brittle API interactions as one-off tools, which raises the question: can Databricks abstract those handoffs so developers can focus on business value rather than plumbing?
The second challenge is vendor resistance. Legacy providers have real incentives to keep control over monetization. If agents drive consumption through APIs, they risk turning a per-seat revenue model into cents-per-call economics. SAP, for instance, OEMs a version of Databricks but also maintains its own data intelligence ecosystem—Data Sphere and Business Data Cloud—designed around its 3D map of enterprise context. That map is not natively interoperable with Databricks. Today, interoperability requires exporting SAP data products via Delta Sharing and vice versa. That’s functional but brittle.
Looking ahead, what would signal real progress? First, Databricks needs to operationalize Agent Bricks with out-of-the-box integrations into platforms like SAP – allowing an agent hosted in Unity Catalog to directly invoke SAP functions. Whether via agent-to-agent communication via MCP or remote API calls by the same protocol, this would close the loop between insight and action across enterprise boundaries.
Longer term, Databricks will need to expand the scope of its data intelligence to incorporate semantics that look more like SAP’s—or even embed SAP’s own 3D models into its native stack. Only then can Databricks hope to compete in mixed estates where operational decisions must cross system boundaries.
The path forward isn’t purely technical – it’s also commercial. Aligning incentives across the stack may prove as challenging as building the technology itself. But if Databricks can deliver a seamless, governed agent layer that unites insight with action, it has a chance to redefine what enterprise applications look like in the AI-native era.
If Databricks can abstract away all the current gaps and friction while generating advanced agentic workflows, it will graduate from an MLOps workbench to an enterprise application platform – one that unifies systems of engagement, intelligence, and agency under a single governed roof.
The Evolving Enterprise Architecture — Crossing the Rubicon to Face New Competitors
As the enterprise stack continues to evolve, the next wave of competition is shifting away from infrastructure and toward control of the semantic layer. At the foundation, the lakehouse and data warehouse incumbents – Databricks and Snowflake – remain locked in a high-stakes race for governance and intelligence mindshare. Databricks is pushing customers toward Unity Catalog as the unified semantic and policy layer, while Snowflake is bleeding Horizon functionality into Polaris, trying to extend native governance into the open Iceberg ecosystem.
But the battle intensifies as we move up the stack.
Exhibit 13 below brings us full circle. Our layered diagram maps today’s competitive fronts: Infrastructure (data platform), Platform (System of Intelligence), and Applications, (agents). At left, the System of Engagement column lists several BI players including Hex, Sigma, Databricks One and Power Platform. The right-side call-outs label the domains in the stack. Three “Open Issues” bullets top the slide:
- Highest value capture accrues to whoever operationalizes decisions, hence fierce competition for SoI real estate.
- Agents “programmed” only by metrics & dimensions remain analytic.
- Operationalizing agent decisions will require updating SoR—either natively or via interim MCP connectors.

Why This Matters
The engagement tier is fragmented and expanding quickly. Power BI, Hex, Sigma, and others are defining new interaction models for business users. Meanwhile, an entirely different cohort – Celonis, Salesforce Data Cloud, SAP’s Business Data Cloud, Palantir, RelationalAI, Blue Yonder, ServiceNow and others – are positioning themselves as systems of intelligence for specific enterprise domains. Each claims to offer the operational context needed for agents to function reliably.
Overlay that with newcomers like Atlan, which aim to sit atop the stack as governance and metadata control planes, and players like UiPath pushing agentic orchestration, and the field becomes even more complex. The prize for software companies is no longer data management, nor even compute engines. It’s harmonization and governance of all application semantics. It’s about who owns the model of the business – and how that model gets governed, enriched, and used by agents to drive action.
This is where the most critical questions emerge:
- Can agents perceive the full state of the business, use a range of analytic tools to make decisions, and update systems of record through the System of Intelligence—not through brittle connectors?
- How does pricing evolve to capture some of the value value when insight turns into action?
The locus of value is moving from storing data to modeling the business. In this new paradigm, the vendor that owns the most widely adopted and richly governed semantic model becomes the operating system for enterprise AI. Agents will only be as effective as the context they are trained on, and that context lives in the system of intelligence.
Databricks’ strength lies in its foundational data platform and a growing commitment to unify analytics, semantics, and agents under one governed roof. But the system of intelligence space is fragmenting fast, and value is emerging in domain-specific islands. Paradoxically, the very fragmentation that these systems were meant to eliminate could become the source of the next layer of abstraction.
If vendors can bridge these semantic islands at the 4D map level—modeling not just what happened, but why, what’s likely to happen, and what should be done—they could unlock a new era of interoperability that was never possible when integrations were attempted at the system-of-record level.
This is why data intelligence is existential. Not because it’s a buzzword, but because it defines the next layer of enterprise competition. As data intelligence becomes the connective tissue between past context, present action, and future intent, it will determine which platforms evolve from analytic data managers into true enterprise operating systems.
Databricks isn’t alone in this race. But if it can stay ahead by fusing engagement, intelligence, and agency under a governed control plane, it has a chance to lead the enterprise into a new, agentic era of application development and operational transformation.
Toward ‘Enterprise AGI:’ Databricks’ Play for the Holy Grail of Competitive Advantage
In last week’s episode, we unpacked Snowflake’s strategic leap. This week, we’ve put Databricks’ innovation on full display, positioning it within a rapidly evolving enterprise framework. But the real takeaway lies not in the feature wars or benchmark comparisons. The stakes are far higher. This is a race for the future of useful AI in the enterprise – what we call Enterprise AGI.
In prior Breaking Analysis segments, we used the metaphor of the Holy Grail to describe this pursuit. One of the clearest examples comes from JP Morgan Chase, where Jamie Dimon oversees one of the most valuable proprietary data troves on the planet. That data will never touch the open internet. Which means no matter how powerful Sam Altman’s consumer-scale LLMs become, they will never be trained on that corpus. They won’t be able to use JP Morgan’s intelligence to help JPM’s competitors. Ironically, long after we published that segment, Ali Ghodsi showcased Jaimie Dimon in person at the end of his first day keynote.

JPMorgan’s data creates a new kind of moat – one defined by governance, perimeter-residency, and domain-specific intelligence. And it reframes the race entirely. Future competition between AI vendors won’t be fought on public LLM benchmark leaderboards. It will hinge on who can turn private, regulated, high-value data into autonomous decision loops – ones that take action at scale, under full corporate governance. That’s the finish line Jamie Dimon and other CEOs are watching.
Databricks is trying to become the on-ramp to that destination. By starting to build semantics into the data platform and building an emerging agentic layer, the company is positioning itself as the bridge between the world of frontier models and the guarded, real-world data where economic value lives. The outcome won’t depend on the biggest model – it will come down to who can translate proprietary data intelligence into action within the bounds of enterprise trust and control.
Data intelligence will be the differentiator in our view. It’s what will allow generic frontier models to be specialized and converted into use “enterprise AGI.” Whether or not a singular AGI “Messiah” ever arrives, enterprise AI will unfold differently. It will be built not on public data but on proprietary maps – semantic systems of intelligence that represent the operational truth of a business.
When that happens, every enterprise that models its data this way can drive agents as intelligent – and as operationally effective – as those powering Amazon’s internal systems. That’s the foundation for the next productivity revolution: a shift from siloed knowledge work to a kind of managerial assembly line, where analytics and intelligent agents inform every role, every process, every decision.
The path to enterprise AGI won’t be outsourced to the internet data frontier labs use for training. It will be built inside the enterprise, behind the firewall, one domain-specific system of intelligence at a time. And in that world, the real competition isn’t between AI companies – it’s between enterprises that model their data, and those that don’t.
Milestones to watch
- Unity Catalog depth – Does the ontology expand beyond 2.5-D metrics to full application schemas that encode policy and process?
- Agent Bricks write-back – When an agent can update an SAP order, a ServiceNow ticket, or a Salesforce opportunity without brittle glue code, the loop will be closed.
- Ecosystem commitment – Track whether BI, ETL, and low-code vendors truly round-trip semantics through Unity rather than hoarding their own.
- Regulatory certifications – FedRAMP High, HIPAA, FINRA, and region-specific sovereignty stamps will be gating items for heavily regulated estates.
Bottom line
Whoever supplies the on-prem, governed substrate that marries private data assets with agentic automation will win disproportionate economic rent. Databricks has a credible line of sight to that position; Snowflake, SAP, Salesforce, ServiceNow, and Blue Yonder are sprinting there as well.
We’ll be tracking which vendor first turns proprietary data into autonomous action loops—because that, not synthetic benchmarks, is the holy-grail finish line Jamie Dimon and every other CEO cares about.


